




Data science is the field of study that uses scientific methods, programming skills, mathematics and statistics to extract meaningful insights from vague and unstructured data. Having its earliest traces during the mid 1970s, Data science is one of the fastest growing occupations of the modern world.
Data science is an interdisciplinary field, that is, it involves the use of multiple academic disciplines. Computer science, mathematics and statistics are its foundation blocks. Other skills like data sonification, data integration, information science, information visualization and graphic design are also incorporated by data science.
Some examples of usage of data science include :- predicting demand for a product, optimizing shipping routes in real-time, automating digital ad placement, stamping out tax fraud, understanding patterns of reservations for airlines, hotels, restaurants, etc.

Programming Languages for Data Science
This section focuses on some of the most popular programming languages used in data science. Equipping yourself with more than one programming language can guarantee to help you overcome unique challenges while dealing with the data. If you are just beginning your journey as a Data Scientist, you should start with the programming languages mentioned below as they are the most in-demand languages right now.
Python
Python is an object-oriented, easy to use and extremely developer-friendly programming language, which also happens to be the go-to choice for domains such as Machine Learning, Deep Learning and Artificial Intelligence.

One of Pythons best qualities is its vast ecosystem of rich libraries which make it ideal for a broad range of purposes. It is also useful for tasks like data collection, analysis, modeling, and visualization and contain multiple ways for exporting and importing files. On top of all this, Python also offers support for powerful Data Science libraries such as Keras, Scikit-Learn, matplotlib and TensorFlow.
To get the best possible understanding of Python, you can read my detailed article on the language here.
JavaScript
JavaScript is a multi-paradigm and event-driven scripting language mostly known for web development. This property makes it desirable for creating brilliant visualizations.

Apart from creating visualizations, JavaScript can be used for managing asynchronous tasks and handling real-time data. In addition to all this, JavaScript supports modern-day Machine Learning libraries such as TensorFlow.js, Keras.js, and ConvNetJs.
To get the best possible understanding of JavaScript, you can read my detailed article on the language here.
Java
Java has been long used by some of the top businesses for secure enterprise development as their preferred development stack of choice. As for Data science, Java offers tools such as Hadoop, Spark, Hive, Scala, and Fink.

Java Virtual Machines are a popular choice for developers to write code for distributed systems and data analysis. Along with this, Java offers several IDEs for rapid application development, supports effortless scaling to build complex applications from scratch and delivers the outcome at a quick pace.
To get the best possible understanding of Java, you can read my detailed article on the language here.
R
The programming language R is specialized for handling the statistical and graphics side of things in Data Science. It provides a number of high quality statistical computing options such as time series analysis, clustering, statistical tests, linear and non-linear modeling .

Third-party interfaces like RStudio and Jupyter make it easier to work with R. R provides excellent extensibility, often allowing other programming languages to modify data objects in R comfortably. On top of all this, R offers efficient handling of data and additional data analysis tools, helps create top quality plots and extends functionality with built in packages.
To get the best possible understanding of Java, you can read my detailed article on the language here.
Data Science Algorithms
In programming, an algorithm is a process or set of rules to be followed in order to achieve a particular goal. Knowing data science algorithms through and through is deemed to be one of the most important skills in data science. These algorithms play an important role in tasks like prediction, classification, and clustering from the data set in concern. The following is a brief introduction to some popular Data Science algorithms.
Linear Regression
The Linear regression algorithm is used for predicting the value of the dependent variable by using the values of the independent variable. This model is suitable for predicting the value of a continuous quantity.
Logistic Regression
The Logistic regression algorithm is used to find the most common application in solving the binary classification problems. In binary classification problems, there are only two possibilities of an event, either the event will occur or it will not occur. Contrary to Linear Regression, Logistic Regression works on discrete values.
Decision Trees
Decision trees are used to help solve both classification and prediction problems. Decision trees make understanding the data easier, which increases the chances of a more accurate prediction.
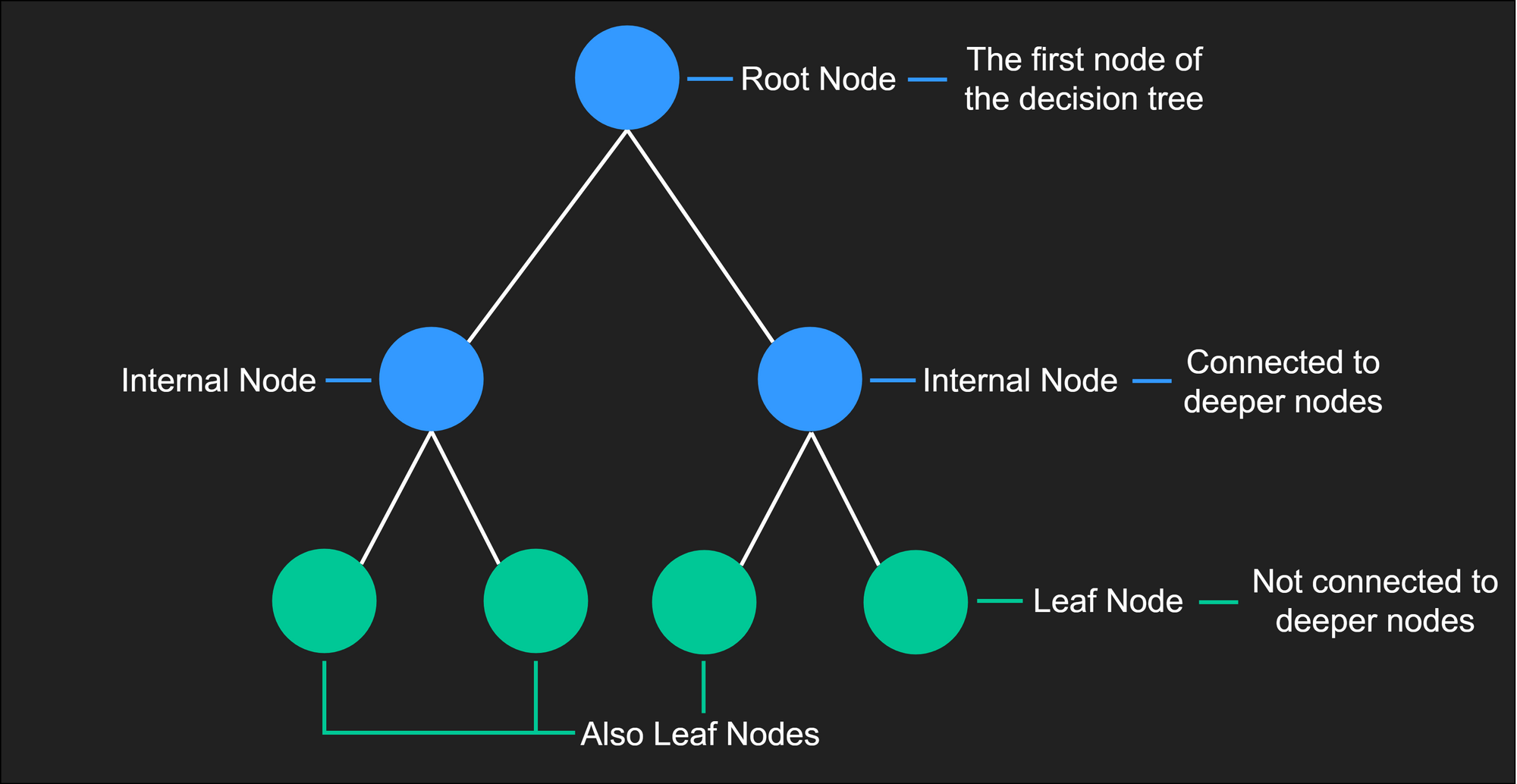
A decision tree consists of :-
root and internal nodes, which represent attributes
links, which represents decisions
leaf nodes, which holds the outcome
Naïve Bayes
Naïve Bayes algorithm is used when their is a need to evaluate the possibility of occurrence of an event. It helps in the construction of predictive models.
This algorithm assumes that each feature is independent and has an individual contribution to the final prediction.
Principal Component Analysis
Principal Component Analysis (PCA) is a technique used for performing dimensionality reduction of the datasets with the least effect on the variance of the datasets. In other words, it removes the redundant features but keeps the important ones. To achieve this, PCA transforms the variables of the dataset into a new set of variables which represents the principal components.
KNN
K-Nearest Neighbors algorithm, or simply KNN, employs both classification and regression problems.
The KNN algorithm considers the complete dataset as the training dataset. After training the model with the help of KNN algorithm, the next step is to predict the outcome of a new data point. Here, the KNN algorithm searches the entire data set for identifying the k most similar or nearest neighbors of that data point. It then predicts the outcome based on these k instances.
Support Vector Machine
Support Vector Machine algorithm, or simply SVM, also employs both classification and regression problems, similar to KNN algorithm.
It is most commonly used for classification of problems and classifies the data points by using a hyperplane.
The first step of this Data Science algorithm involves plotting all the data items as individual points in an n-dimensional graph. Here, n is the number of features which is also the value of each specific coordinates. Then, the next step is to find the hyperplane that best separates the two classes for the purpose of classifying them.

Is learning Data Science worth it?
Recently, data science has emerged as one of the most prominent career choices, both for the graduates who are just starting their carriers and for working professionals across a broad hierarchical range. The demand for data scientists has grown remarkably due to the urgent requirement for strategic decision-making tailored for specific branches.
The potential for data science is huge in the future. The demand for trained professionals in the field seems to continue rising at a fast rate. Thus, Investing your time and effort in data science will be worth it.